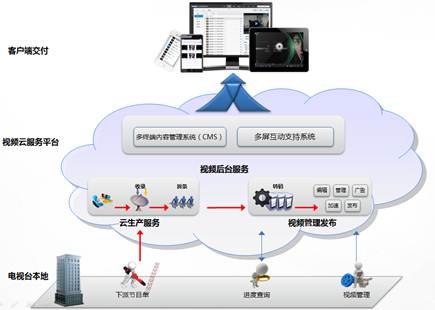
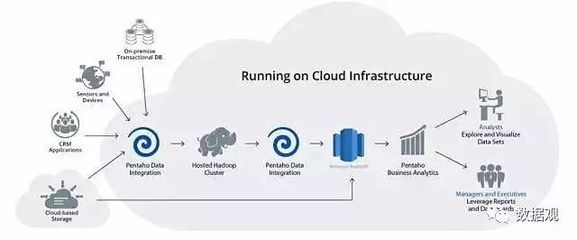
大數據行業生態全景 以基礎軟件服務為核心的科技基石
大數據行業已從單一技術概念演變為一個龐大且層次分明的生態系統。這個生態系統以基礎軟件服務為堅實底座,向上支撐著數據應用、分析洞察乃至最終的商業與社會價值實現。
一、 生態結構總覽
大數據行業生態可宏觀地劃分為四個核心層次,自下而上分別為:基礎設施層、數據管理層、分析計算層與數據應用層。這四個層次相互依存,共同構成數據從原始狀態到智慧決策的價值轉化鏈條。
二、 核心基石:基礎軟件服務
基礎軟件服務主要分布在生態的前三個層次,是整個大數據體系的“操作系統”和“發動機”。
- 基礎設施層
- 核心組件:以云計算平臺(如AWS、Azure、阿里云) 和容器化/編排工具(如Kubernetes、Docker) 為代表。它們提供了彈性可擴展的計算、存儲和網絡資源,是大數據得以存續和處理的物理與虛擬基礎。
- 數據管理層
- 核心組件:這是基礎軟件服務的核心競技場,包括:
- 數據集成與采集工具:如Apache Kafka(流數據)、Flume、Sqoop,負責從各種源頭實時或批量獲取數據。
- 數據存儲系統:涵蓋關系型數據庫、NoSQL數據庫(如MongoDB、Cassandra)、NewSQL、以及專為大數據設計的分布式文件系統(如HDFS)和對象存儲。
- 數據治理與目錄工具:如Apache Atlas、Collibra,負責元數據管理、數據質量、血緣追蹤和安全合規,確保數據的可信與可用。
- 分析計算層
- 核心組件:提供數據處理和分析能力的軟件框架與引擎。
- 批處理引擎:Apache Hadoop MapReduce(雖在演進,仍是經典)。
- 流處理引擎:Apache Flink、Apache Storm、Spark Streaming,滿足實時計算需求。
- 交互式查詢引擎:Apache Hive、Presto、ClickHouse,支持對海量數據的快速即席查詢。
- 機器學習/人工智能框架:TensorFlow、PyTorch、Spark MLlib,賦能數據智能。
三、 基礎軟件服務的核心價值與趨勢
- 價值體現:
- 解耦與標準化:將底層硬件復雜性抽象化,使上層應用能專注于業務邏輯。
- 規模化與高性能:通過分布式架構,處理PB乃至EB級數據成為可能。
- 降低技術門檻:成熟的托管服務和平臺化產品(如云上的EMR、Databricks)讓更多企業能夠快速構建大數據能力。
- 發展趨勢:
- 云原生與Serverless化:軟件服務深度融入云環境,按需使用、自動擴縮容成為主流。
- 實時化與一體化:流批一體的處理框架(如Flink)正模糊批與流的界限,滿足更快的決策需求。
- 湖倉一體與數據編織:打破數據湖與數據倉庫的壁壘,構建統一、靈活、智能的數據架構(如Delta Lake、Snowflake的理念)。
- 開源與商業的協同:開源社區(Apache基金會等)是創新的源頭,商業公司在此基礎上提供企業級支持、托管服務和增值功能,形成健康雙軌制。
四、 對上層應用的影響
穩固、高效、易用的基礎軟件服務,直接催生了頂層數據應用層的繁榮,包括但不限于:
- 行業解決方案:精準營銷、風險控制、智能運維、智慧城市等。
- 數據產品與數據服務:面向內外部用戶的報表平臺、數據API、智能推薦系統等。
- 決策支持系統:基于數據的戰略分析、商業智能(BI)與可視化。
###
大數據行業的生態系統如同一座摩天大樓,基礎軟件服務就是其深埋地下的地基與承重結構。它雖不直接面向最終用戶,卻決定了整個系統的高度、穩固性和擴展性。隨著技術不斷演進,基礎軟件服務正朝著更智能、更融合、更易用的方向發展,持續為數據價值的全面釋放提供核心驅動力。
(附圖示意:一個四層金字塔結構圖,從上至下依次為:數據應用層 -> 分析計算層 -> 數據管理層 -> 基礎設施層。其中,數據管理層、分析計算層和基礎設施層被顯著標注為“基礎軟件服務核心區”,并通過箭頭顯示數據自下而上的流動與價值提煉過程。)
如若轉載,請注明出處:http://www.ron21l.cn/product/36.html
更新時間:2026-01-07 09:08:51